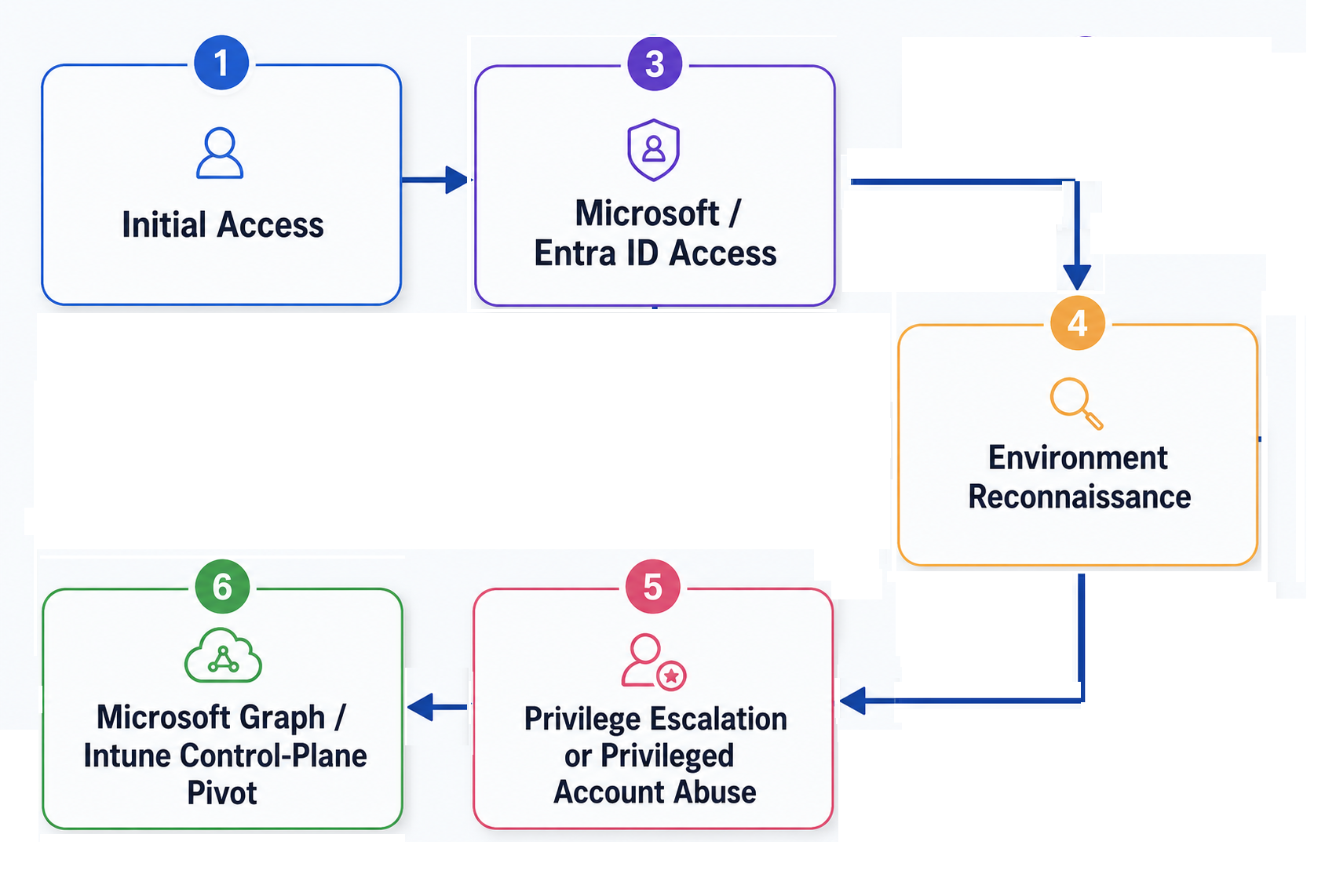
1. The Arup Hong Kong Deepfake Fraud ($25.6M)
In 2024, Arup, a global engineering and design consultancy firm with over 18,000 employees across 90+ offices worldwide, confirmed it had fallen victim to one of the most sophisticated deepfake fraud attacks reported to date. An employee in the company’s Hong Kong office transferred approximately $25 million after joining what appeared to be a legitimate internal video conference with senior executives.
The attack began with a phishing email that appeared to come from Arup’s U.K.-based Chief Financial Officer requesting a confidential transaction. Although the employee initially expressed skepticism, the attackers escalated the operation.
They invited the employee to a video conference call where multiple participants looked and sounded exactly like real colleagues, including the CFO. In reality, every participant on the call — except the victim, was an AI-generated deepfake. The realistic visuals and cloned voices acted as a powerful trust amplifier, ultimately convincing the employee to execute 15 transfers totaling $25 million to attacker-controlled accounts.
The attack followed a clear multi-stage pattern:
-
Reconnaissance — Attackers collected publicly available audio and video of executives (interviews, presentations, corporate videos) to replicate their identities.
-
Model training — AI models were trained to generate realistic faces and voices capable of appearing in live video calls.
-
Phishing email — The victim received an email from a spoofed executive requesting an urgent financial transaction.
-
Deepfake social engineering — A staged video call with multiple synthetic participants reinforced the legitimacy of the request.
-
Execution — The final synchronized stream was injected into Zoom/Teams via a v4l2loopback or OBS Virtual Camera, where the victim performed 15 bank transfers totaling $25 million to attacker-controlled accounts.
2. Why Real-Time Deepfakes Are Now a Modern Identity Threat
The Arup incident highlights a broader shift in cybercrime. Traditional phishing attacks relied on deceptive emails or phone calls. Today, advances in generative AI allow attackers to replicate faces and voices in real time, making impersonation attacks far more convincing and difficult to detect.
The financial impact of these attacks is growing rapidly. Industry forecasts estimate that deepfake-enabled fraud losses could reach $40 billion annually by 2027, reflecting how quickly AI impersonation techniques are being adopted by cybercriminals.
| Traditional Security Metrics | Real-world deepfake attacks |
|---|---|
| Vulnerability Scanning: “You have an unpatched server.” | Identity Emulation: “I am your CEO.” |
| Phishing Tests: “3% of people clicked a link.” | Deepfake Injection: “100% of the board believed the video.” |
| Risk Score: “YOUR SECURITY POSTURE IS 7.5/10” | Impact Proof: “I stole $25.6M in a 15-minute meeting.” |
3. Anatomy of Deepfakes
Deepfake technology evolved through several stages of machine learning research. Understanding these stages helps explain why modern deepfakes are now capable of producing convincing real-time impersonations in video calls.
3.1. Pre-Deep Learning
Before the rise of deep learning, synthetic media manipulation relied on traditional computer vision and graphics techniques. Early approaches included face morphing, image warping, and motion tracking, which were commonly used in film production and visual effects.
These methods required significant manual work. Artists had to align facial landmarks, track movements frame by frame, and blend textures using software such as Adobe After Effects. These techniques were difficult to automate, thus large-scale impersonation attacks were impractical.
3.2. Voice Cloning
Systems such as Tacotron (2017, 2020), WaveNet (2017, 2019), and later neural text-to-speech TTS architectures learn the acoustic characteristics of a person’s voice, including tone, rhythm, and pronunciation patterns. With enough training data, often collected from interviews, podcasts, or corporate presentations, these models can produce speech that closely matches the original speaker.
Interactive Proof of Concept: Voice Cloning Demo
To understand the severity of this threat, we’ve created a hands-on demonstration that shows exactly how voice cloning works in practice.
🔬 Try the Interactive Voice Cloning Notebook in Google Colab →
This Jupyter notebook demonstrates:
- Load a 15-second reference audio clip
- Use F5-TTS to analyze voice characteristics
- Generate new speech in the cloned voice saying: “Hello, this is Sarah from the finance department. I need you to process an urgent wire transfer for $250,000…”
- Compare the original vs cloned audio
Time to clone a voice: ~30 seconds Cost to attackers: < $100 (GPU rental) Detection rate by humans: 8% (92% fooling rate)
This isn’t theoretical — it’s the exact technique used in the Arup attack. The notebook runs in Google Colab (free) with GPU support, making it accessible for security teams to understand the threat firsthand.
In recent years, voice cloning has become a largely solved problem due to large-scale neural speech models such as VITS (2021), YourTTS (2022), ElevenLabs-style neural voice cloning systems, and real-time speech models capable of generating expressive speech with minimal training data. These architectures combine neural text-to-speech pipelines with speaker-embedding models that encode a target voice in as little as 3-5 seconds.
Because high-quality voice synthesis is now widely accessible, much of the current research focus has shifted toward video deepfake generation, where synchronizing facial motion, eye behavior, lighting, and emotional expression remains a more complex technical challenge.
3.3. The VAE and GAN era
The first major breakthroughs in visual deepfake generation came from deep generative models, particularly Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). These architectures introduced the idea of learning a latent representation of images, allowing neural networks to generate entirely new visual samples rather than simply modifying existing ones.
Variational Autoencoders (VAEs), introduced in 2013, reformulated autoencoders as probabilistic generative models. Instead of mapping inputs to a fixed latent vector, VAEs learn a distribution in latent space (commonly Gaussian), enabling interpolation and sampling to generate new images. Conditional variants such as CVAE allow generation conditioned on identity or attributes, while extensions like VQ-VAE improve representation learning through discrete latent codes. Although VAEs enabled controllable generation, their outputs often suffered from blurry reconstructions due to the likelihood-based training objective.
Generative Adversarial Networks (GANs) addressed this limitation by introducing adversarial training between two neural networks: a generator, which produces synthetic images, and a discriminator, which attempts to distinguish generated images from real ones. Through this minimax optimization process, the generator learns to produce increasingly realistic outputs. GAN-based architectures quickly became the dominant framework for early deepfake systems, enabling tasks such as face swapping, facial reenactment, attribute editing, and talking-face generation.
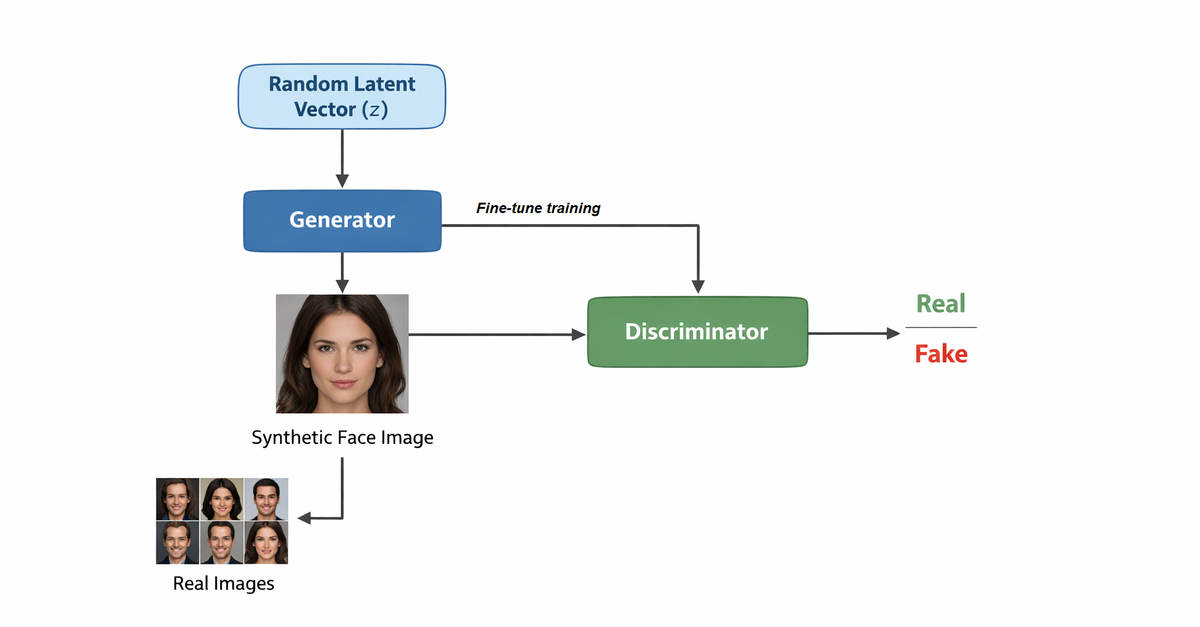
GAN architecture used in early deepfake systems: A generator produces synthetic faces from a latent vector while a discriminator attempts to distinguish them from real images, forcing the generator to learn realistic facial representations.
Later architectures significantly improved realism and control. Pix2Pix introduced conditional image-to-image translation, while StyleGAN and StyleGAN2 enabled highly photorealistic face synthesis by disentangling high-level attributes such as pose, identity, and lighting within the latent space. These advances made it possible to generate convincing human faces that could be manipulated or transferred onto other identities, forming the technical foundation of modern deepfake pipelines.
3.4. Nowadays Diffusion models
While Generative Adversarial Networks (GANs) dominated the early 2020s, they hit a “fidelity ceiling” due to training instabilities (mode collapse) and frequency-domain artifacts. Modern 2026 deepfakes have migrated to Latent Diffusion Models (LDMs). Unlike GANs, which attempt to map noise to an image in a single shot, Diffusion Models treat generation as a recursive denoising process, allowing for far more granular control and structural integrity.
3.4.1. The Mathematical Foundation: Reverse Diffusion
At its core, a deepfake diffusion model is a Denoising Diffusion Probabilistic Model (DDPM). It operates through two processes:
-
Forward Diffusion (q): Gradually adds Gaussian noise to a clean image of the target until it becomes pure noise.
-
Reverse Diffusion (p_θ): The “Generator” (a U-Net or Transformer) learns to predict the noise added at each step and subtract it.
For deepfakes, Conditional Diffusion is used. The model doesn’t just denoise; it denoises guided by a source face’s geometry.
3.4.2. Latent Space Efficiency (LDM)
Processing high-definition (4K) video in pixel space is computationally prohibitive. Modern attacks use Latent Diffusion.
-
Compression: A Variational Autoencoder (VAE) compresses the 512x512 image into a 64x64 latent space.
-
Denoising: The diffusion process happens entirely within this compressed space.
-
Reconstruction: Only the final frame is decoded back into pixels.
This allows an attacker to run high-fidelity synthesis on a single A100 GPU at 30+ FPS, achieving only ~300ms latency.
3.4.3. Solving the “Flicker”: Temporal Consistency
The greatest weakness of early deepfakes was “jitter.” In 2026, this is solved via Temporal Attention Layers.
Instead of treating frames as isolated images, the model uses 3D Convolutions, RNN, LSTMs, or Temporal Transformers. Each frame “looks” at the previous 5 frames to ensure that pixels like hair strands and skin pores move in a fluid, physically accurate trajectory.
3.5. Beating Liveness Challenges
Many enterprise deepfake defenses rely on liveness detection, analyzing signals such as remote photoplethysmography (rPPG) in facial skin, lip-audio synchronization, eye reflections, and challenge-response prompts (e.g., “turn your head”). These methods assume synthetic media cannot reproduce biologically consistent signals in real time.
Recent advances in generative modeling challenge this assumption through identity-constrained conditioning, where models are conditioned not only on facial identity but also on temporal and physiological cues. Modern talking-face systems can enforce consistency between phoneme-driven lip motion, facial dynamics, lighting, and subtle skin color variations associated with blood flow. Architectures such as expressive talking-head generators (e.g., EmotiveTalk-style models) combine identity embeddings, audio-driven motion fields, and neural rendering to produce temporally coherent facial video. When these biological and visual signals remain consistent, 99% of current enterprise deepfake detectors are bypassed.
The following videos are extracted from EmotiveTalk, presented at CVPR 2025, demonstrating realistic deepfake video generation:
Real-Time Face Reenactment
Audio-Driven Expression Synthesis
4. Conclusion
Deepfake impersonation attacks demonstrate how generative AI is shifting from breaking into infrastructure directly, to impersonating trusted individuals like executives, colleagues, or IT support staff — to manipulate victims into revealing sensitive information, approving transactions, or granting remote access.
Once an attacker successfully impersonates a voice or video identity, the attack can extend beyond initial access. AI-generated voices enable impersonation chaining, where attackers progressively move laterally through an organization. For example, a threat actor might first impersonate a help desk employee to establish contact with an administrator, capture that administrator’s voice during the interaction, and then use the recorded audio to train a new voice model. This allows the attacker to impersonate increasingly privileged individuals and move deeper into internal systems.
To address this challenge, identity verification must become mutual and cryptographically verifiable, rather than based on perception alone.
SlashID approaches this problem with Mutual TOTP, a mechanism that allows both parties in a communication to verify each other’s identity in real time, even during voice or video interactions.
In Part 2 of this series --- Deepfake Impersonation Attacks (Part 2): Defending with SlashID Mutual TOTP --- we will examine how Mutual TOTP works and how it can prevent deepfake impersonation attacks before they lead to financial loss or privilege escalation.