Introduction
Guaranteeing high availability is a key aspect of API security. At a high level, a rate limiter governs how many requests a given entity (e.g., a user or an IP address) can issue in a specific window of time (e.g., 200 requests per minute).
If you’re a company building web applications and APIs at large scale, a good rate limiter can prevent users and bots from harming your website’s availability with a spate of requests while also stopping spam, DDoS, scraping, and credential stuffing attacks.
For modern applications it is key for any rate limiter to have the following additional features:
- Support for distributed rate limiting across microservices
- Does not appreciably slow down web requests
- Block/limit requests based on the identity of the request and not just the IP address
- Have granular control over which endpoints are rate limited
- Have different rate limits for different groups of customers depending on certain factors (e.g., subscription tier)
On top of the characteristics above, our implementation of rate limiting has several further advantages:
- It supports multiple limits at the same time instead of a single one (see below for a real world example)
- It supports multiple storage backends depending on performance and accuracy requirements
- It supports the ability to use JSONPath to enforce rate limiting based on any part of the request, including JSON Web Token (JWT) claims
- It supports a webhook for more complex identity-based rate limiting logic
- It supports throttling, so requests are delayed rather than simply blocked
Gate is our identity-aware edge authorizer to protect APIs and workloads that implements the rate limiting plugin we’ll describe below.
Gate can be used to monitor or enforce authentication, authorization and identity-based rate limiting on APIs and workloads, as well as to detect, anonymize, or block personally identifiable information (PII) exposed through your APIs or workloads.
You can find more about Gate in the developer portal.
Background: Common rate limiting approaches
The most common rate limiting algorithms are:
- Fixed window counters
- Sliding window log
- Token bucket
- Leaky bucket
Fixed window counters
In this algorithm, the rate limiter divides time into fixed windows per user and maps incoming events into these windows. If a user exceeds the allowed number of requests in a given window, the remaining requests are dropped.
Implementation is straightforward - for each user/IP address:
- The rate limiter splits the timeline into fixed-size time windows and assigns a counter for each window
- Each request increments the counter by one in the relevant window
- Once the counter reaches the pre-defined threshold, new requests are dropped until a new time window starts.
This algorithm is rarely seen in the wild but it creates the foundation for the others we’ll discuss below. Fixed window counters is the most easily scalable rate limiter and can be implemented with an atomic increment-and-get operation (e.g., INCR command on Redis), unlike other algorithms that require multiple steps and therefore each check needs to be performed sequentially.
The main issue with this algorithm is that it can be gamed by spiking traffic at the end of each window. In other words, since the windows are fixed, an attacker can use the fixed window and shift his request patterns by a certain delta to, in the worst case, double the allowed number of requests per window.
For instance, if the rate limiter allows a maximum of 1000 requests for each one-minute window, then 1000 requests between 1:00:00 and 1:01:00 are allowed and 1000 more are allowed between 1:01:00 and 1:02:00. However, if all the requests are sent between 1:00:30 and 1:01:30, 2000 requests will be allowed in a one-minute interval.
Sliding window log
The sliding window log is another approach that addresses this issues of fixed window counters. In this algorithm, the rate limiter tracks a timestamped log for each user request. These logs are usually stored in a hash set or table that is sorted by time. Logs with older timestamps outside the window are discarded. When a new request comes in, the rate limiter counts the logs for that user to determine the request rate. If the request exceeds the threshold rate, then it is discarded.
The advantage of this algorithm is that it does not suffer from the boundary conditions of fixed windows. The disadvantage is that it is very memory inefficient.
Token Bucket
Wikipedia has a good explanation of the algorithm. Conceptually the idea is that you allow requests through until the “bucket” for that user is empty and when that happens you discard further requests until the bucket is refilled.
Practically, for each user/IP address you keep track of, you would save the request timestamp and available token count.
Whenever a new request arrives from a user, the rate limiter fetches the timestamp and available token count based on a chosen refill rate. Then, it updates the tuple for the user with the current request’s timestamp and the new available token count - in other words, the delta between the last timestamp and the current one dictates how many extra tokens should be added to the bucket. When the available token count drops to zero, the rate limiter knows the user has exceeded the limit.
The key benefit of this algorithm is that its memory footprint is extremely limited and its speed of execution is very fast. However depending on the implementation atomicity is hard to guarantee which could lead to some requests evading the limit.
Leaky Bucket
This algorithm is similar to the token bucket. When a request is registered, it is appended to the end of a queue. At a regular interval, the first item in the queue is processed. If the queue is full, then additional requests are discarded (leaked).
The advantage of this algorithm compared to the token bucket is that it smooths out bursts of requests and processes them at an approximately constant rate.
The disadvantage is that it’s hard to implement in a distributed setting and it’s hard to guarantee atomicity in this case as well.
The rate limiting implementation in Gate
Chosen algorithm: Generic cell rate algorithm
For our implementation, we decided to use the generic cell rate algorithm (GCRA), which is a token bucket-like algorithm.
In GCRA the algorithm calculates the timestamp of the next predicted arrival time (called Theoretical Arrival Time) for a request based on the configuration parameters. If the request is early (i.e., non-compliant), the request can either be discarded or marked for potential discard downstream, depending on the rate limiter policies.
There are several advantages to GCRA over the other algorithms discussed:
- Memory efficiency and speed: Rather than physically counting tokens, the timestamp-based method keeps track of the theoretical arrival time (TAT) for the next compliant request. When a request arrives, its arrival time is compared with the TAT. If it’s before the TAT, the request is non-compliant, and if it’s on or after the TAT, the request is compliant. The TAT is then updated based on the interarrival time. Contrary to queue based approaches, this is significantly more memory-efficient without the fixed windows drawbacks,
- Precision: In GCRA, the exact moment when the next request will be allowed is known.
- Double Rate Parameters: GCRA is described with two parameters: a burst rate and a sustained rate. This allows control over both the frequency of requests and the maximum number of requests that can be executed at once.
- Custom parameters per endpoint: GCRA allows to specificy different policies for different endpoints. For example, given “/api/op1” and “/api/op2”, op1 can be limited to 60 ops/minute and op2, being more expensive, can be limited to 5 ops/minute. You just need to guarantee that the
burst / rate(i.e., window size) remains constant when reusing the same ratelimiter
State storage
One key consideration when deciding on state storage is atomicity. As we described in the sections above, certain algorithms (including GCRA) are hard to implement atomically, because more than one operation has to be performed in order to calculate the rate limit. For instance, in a naive implementation of the token bucket, if multiple requests arrive at a very close interval, non-atomicity implies a race condition between the rate limiting updating the bucket for the two requests, potentially resulting in a request above the limit passing through. The bigger the delta between the operation, (e.g., fetching the data and updating it), the easier it is to trigger such a race condition.
To address the atomicity problem, we have implemented two approaches using Redis. The first is a C++ Redis module and the second is a Lua script for Redis. In both instances, Redis guarantees the atomicity of execution.
Gate supports several storage options to keep track of the rate limiter state:
- In memory: Highest performance but only usable in single-process scenarios
- Redis module: Can be distributed and has the best performance of the non-volatile options, but requires the installation of a module in Redis
- Redis Lua script: Best trade-off between performance and easy Redis setup
- Non-atomic Redis: Executes the rate limiting logic in Gate while persisting state in Redis. It is non-atomic and may sometimes exceed the desired rate limit. Only use this if you need to keep your Redis server free of custom code.
Rate limit request fields
It is often necessary to apply independent limits per user (or groups, or any other criteria). To achieve this, the rate limit plugin supports the <Limit Request Field> option. This can be used to specify a JSONPath, which will be used to retrieve the additional information necessary to differentiate between requests.
A few typical examples for the <Limit Request Field> JSONPath selector:
- $.request.http.headers[‘X-User-Id’][0]: Retrieves a user ID from a custom header
- $.request.http.cookies[‘user-id’]: Retrieves a user ID from a cookie
- $.request.parsed_token.payload.sub: Retrieves a user ID from the
subclaim in a JWT.
Map limit endpoint
For more complex scenarios you can use the map limit endpoint. If specified, for every incoming request the rate limiter plugin will make a GET request to the specified endpoint.
The method, path and headers of the original request are forwarded to the mapping endpoint.
The response must be HTTP 200 (OK) and must be JSON-formatted. For example:
{
"limits": [
{
"key": "users/john.smith",
"comment": "username",
"interval": 0.1, // In seconds. Use either interval or burst
//"burst": 10, // Use either interval or burst
"window": 1, // In seconds
"max_throttle": 5 // In seconds
}
]
}You can read more about the rate limit request field configuration in our developer portal
Monitoring Mode
By default, this plugin will automatically reject excessive requests with HTTP error 429 (Too Many Requests), and will automatically sleep before completing the request if throttling is necessary. The plugin will also add headers that you can use to get info about the rate-limiting result.
However, it is possible to let the request go through by enabling monitoring mode. It is then up to your request handler to decide how to proceed when the rate limit is exceeded or requires throttling. This allows to implement “shadow ban” like functionality where an attacker continues to receive a 200 HTTP response code but behind the scenes the rate limiter stopped sending real data after they exceeded the rate limit.
A brief example
Let’s see a Gate configuration example to get a concrete feel of the rate limiter:
gate:
plugins:
- id: ratelimit
type: ratelimit
enabled: false
parameters:
limiter:
type: redis_lua
address: redis:6379
limits:
- key: global
comment: global rate
burst: 10000
window: 1s
- key: username
comment: Username
burst: 600
window: 1m
max_throttle: 3s
request_field: $.request.http.cookies['username']
urls:
- pattern: '*/hello'
target: http://backend:8000
plugins:
ratelimit:
enabled: trueBreaking this down, the first part of the configuration tells Gate that the state storage mode is Redis with the Lua script:
gate:
plugins:
- id: ratelimit
type: ratelimit
enabled: false
parameters:
limiter:
type: redis_lua
address: redis:6379We then proceed to specify the keys on which the rate limiter should operate. In our case we specify a global rate and a rate based on the username of a user:
limits:
- key: global
comment: global rate
burst: 10000
window: 1s
max_throttle: 1s
- key: username
comment: Username
burst: 600
window: 1m
max_throttle: 3s
request_field: $.request.http.cookies['username']In the global case we define a window of 1 second and a burst of 10,000 requests per time window, whereas in the username case we limit the burst to 600 requests per minute.
We throttle requests (before discarding them) for 1 second in the global case and 3 seconds in the username case.
Lastly, we tell the rate limiter to locate the username field in $.request.http.cookies['username'].
Finally, we enable the plugin on the "*/hello" endpoint:
- pattern: '*/hello'
target: http://backend:8000
plugins:
ratelimit:
enabled: truePerformance
Benchmarking the above example on an AMD Ryzen 7 5800X for 30 seconds on localhost with a single instance of Gate, we observe the following:
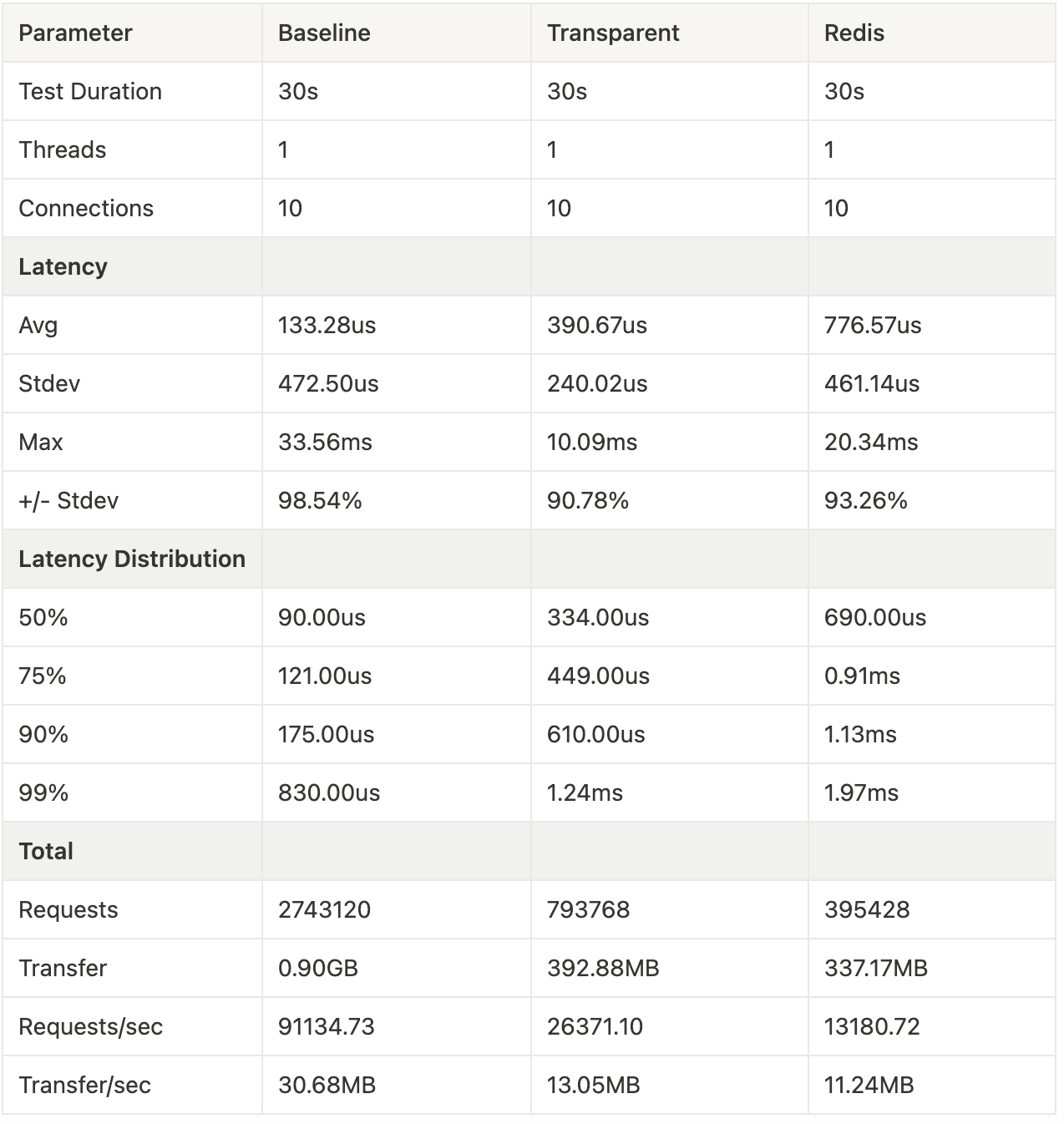
The slowdown incurred by interposing a service between the request and the backend serving “/hello” is approximately 244us and adding the rate limiter adds a further 356 us on top. The rate limiter processes 13,180 requests per seconds.
What happens when the server is maxed out and fully loaded?
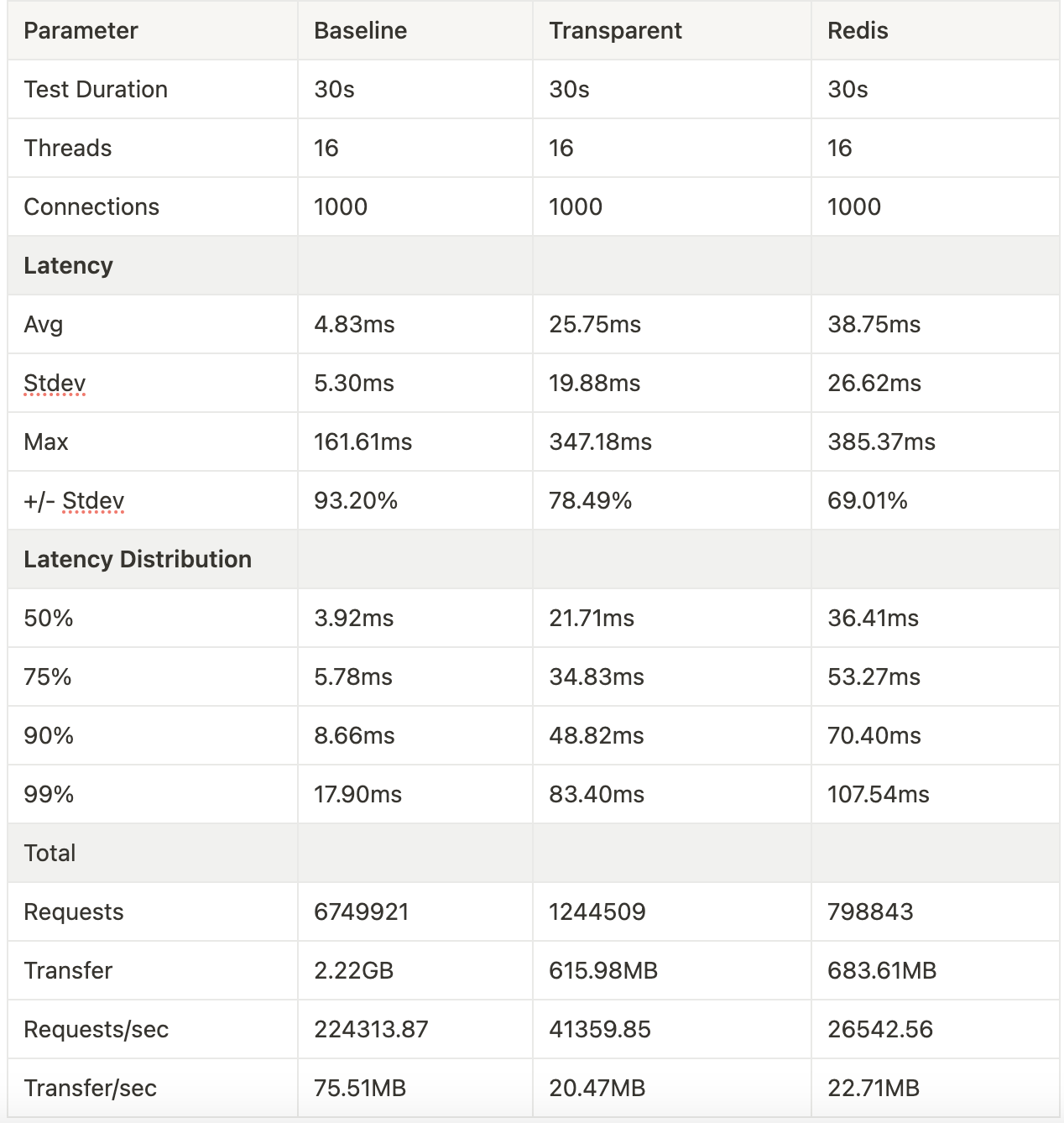
The slowdown caused by the rate limiter goes up to 13ms when all CPUs are busy. In terms of request per seconds, the rate limiter can process 26,542 as a single instance.
While it’s important to compare performance with the system under strain, in the real world, the gate instances would autoscale hence using the data from 10 client threads is a more realistic depiction of how the rate limiter would behave in practice.
Conclusion
Modern rate limiting is a key asset to protect against spam and bots. In this brief blog post, we’ve discussed the most common implementations of rate limiting and our custom one in Gate.
We’d love to hear any feedback you may have. Please contact us at [email protected]! Try out SlashID with a free account.